Graph Attention Networks
Learning how much each neighbor matters.
Motivation
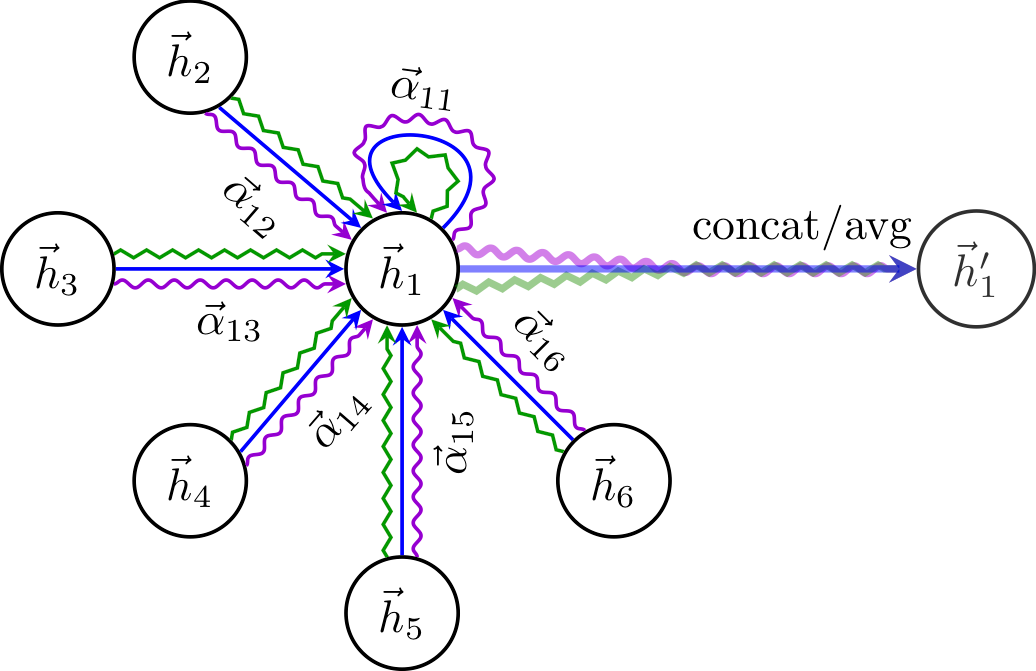
Graph Attention Networks replace fixed aggregation weights with learned attention over a node's neighborhood, letting the model decide which relationships carry information — without needing the full graph structure up front.
Method
For each edge an attention coefficient is computed from the endpoints' features, normalized over the neighborhood, and used to weight the message. Multi-head attention stabilizes learning and captures diverse relational patterns.
\[ \alpha_{ij} = \frac{\exp\!\big(\mathrm{LeakyReLU}(a^\top[Wh_i \,\|\, Wh_j])\big)}{\sum_{k\in\mathcal{N}(i)} \exp\!\big(\mathrm{LeakyReLU}(a^\top[Wh_i \,\|\, Wh_k])\big)} \]
Mathematical core
GAT is self-attention restricted to a graph's edges — the same operator behind transformers, specialized to non-Euclidean, relational domains.