Vision Transformer (ViT)
Images as sequences of patches — attention instead of convolution.
Motivation
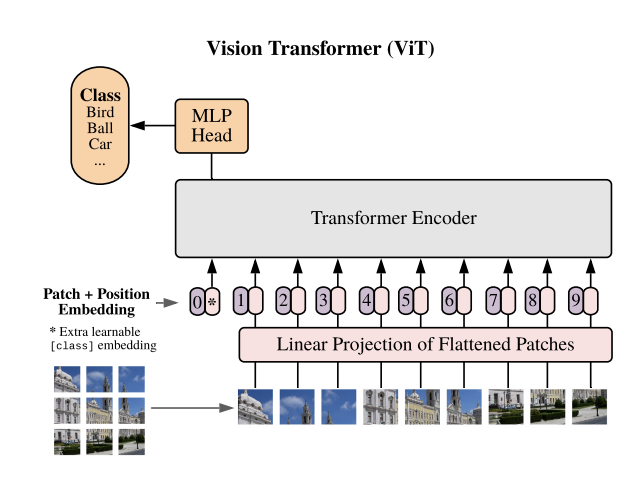
The Vision Transformer shows that the inductive biases of convolution are not strictly necessary: split an image into patches, embed them as tokens, and let self-attention model global relationships directly.
Method
Patches are linearly embedded and augmented with positional encodings and a class token, then processed by a standard transformer encoder. Attention lets every patch attend to every other from the first layer, giving a global receptive field.
\[ \mathrm{Attention}(Q,K,V) = \mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V \]
Mathematical core
Self-attention is a data-dependent, permutation-equivariant mixing operator — a learned, dense analogue of message passing on a complete graph. That connection ties ViTs to my work on graph neural networks.